Research
The Good, the Bad, and the Sampled: a No-Regret Approach to Safe Online Classification
AISTATS 2026 (spotlight)
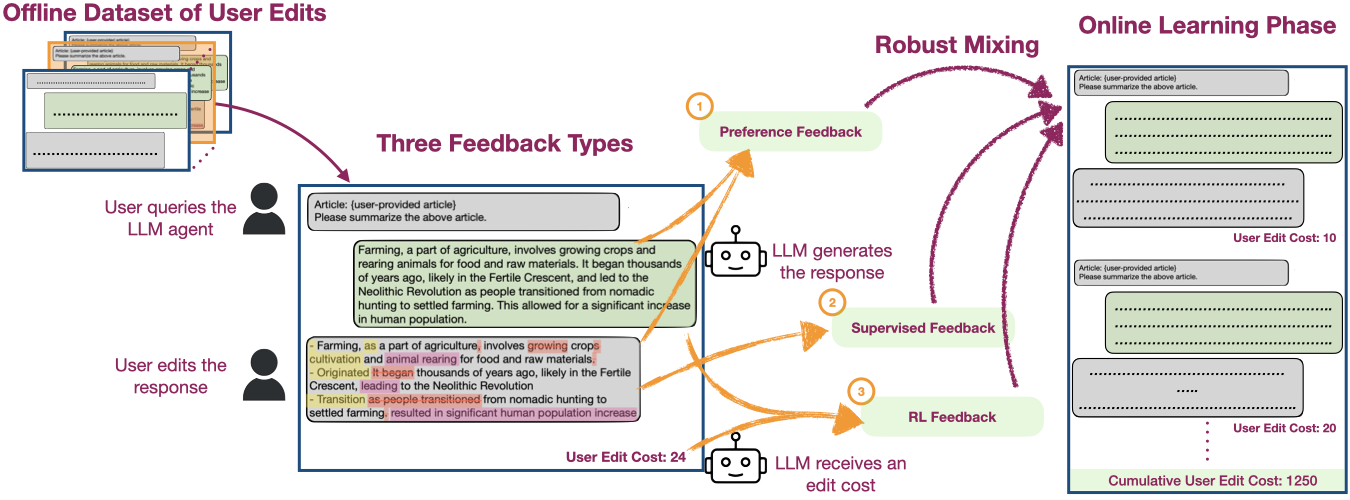
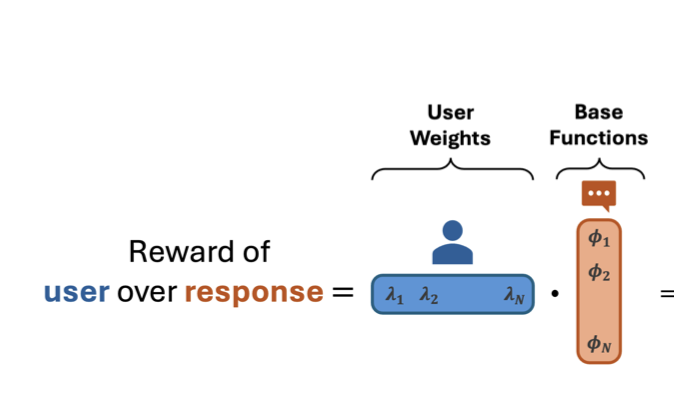
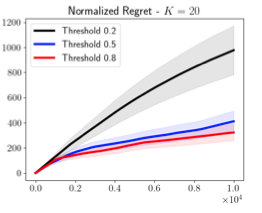
On the Hardness of Bandit Learning
COLT 2025


Active Preference Optimization for Sample Efficient RLHF
ECML-PKDD 2025


Pure Exploration with Feedback Graphs
AISTATS 2025


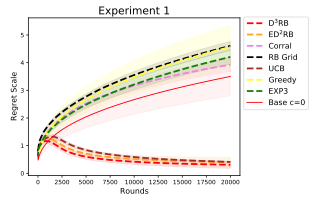
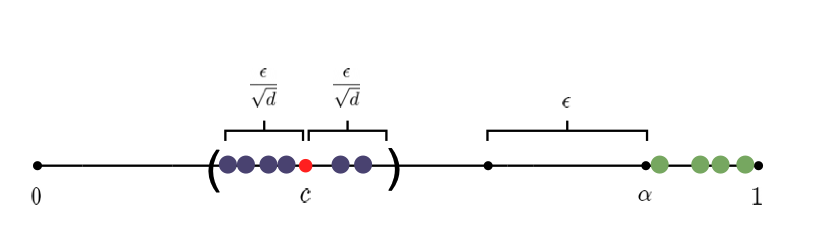
Anytime Model Selection in Linear Bandits
NeuRIPS 2023
Experiment Planning with Function Approximation
NeuRIPS 2023
